テーマ名: 感情を含んだ声を作る!
−韻律の部分空間を用いた感情音声の合成−
森山剛,森真也,小沢慎治:韻律の部分空間を用いた感情音声合成,情報処理学会論文誌,pp.1181-1191, Vol.50, No.3, 2009. (PDF 5.49MB)
森真也,「韻律の部分空間の制約を用いた感情音声合成」,慶應義塾大学大学院理工学研究科修士論文,2005.
本方式は、学習音声に含まれない感情、例えば徐々に強くなる感情が合成できる。
合成する感情 |
文節語(アクセント型、モーラ数) |
与えた感情の強度 |
|---|---|---|
怒り |
/amamizu/ (LHLL、4モーラ) |
|
退屈 |
/aomori/ (LHLL、4モーラ) |
|
喜び |
/arawani/ (HLLL、4モーラ) |
|
悲しみ |
/omoumamani/ (LHLLLL、6モーラ) |
|
嫌悪 |
/naname/ (LHL、3モーラ) |
|
落胆 |
/oborozukiyo/ (LHHHHL、6モーラ) |
*** 感情ベクトルeとして、[6 0 0 0 0 0 0 0 0 0 0 0]T を与えた。
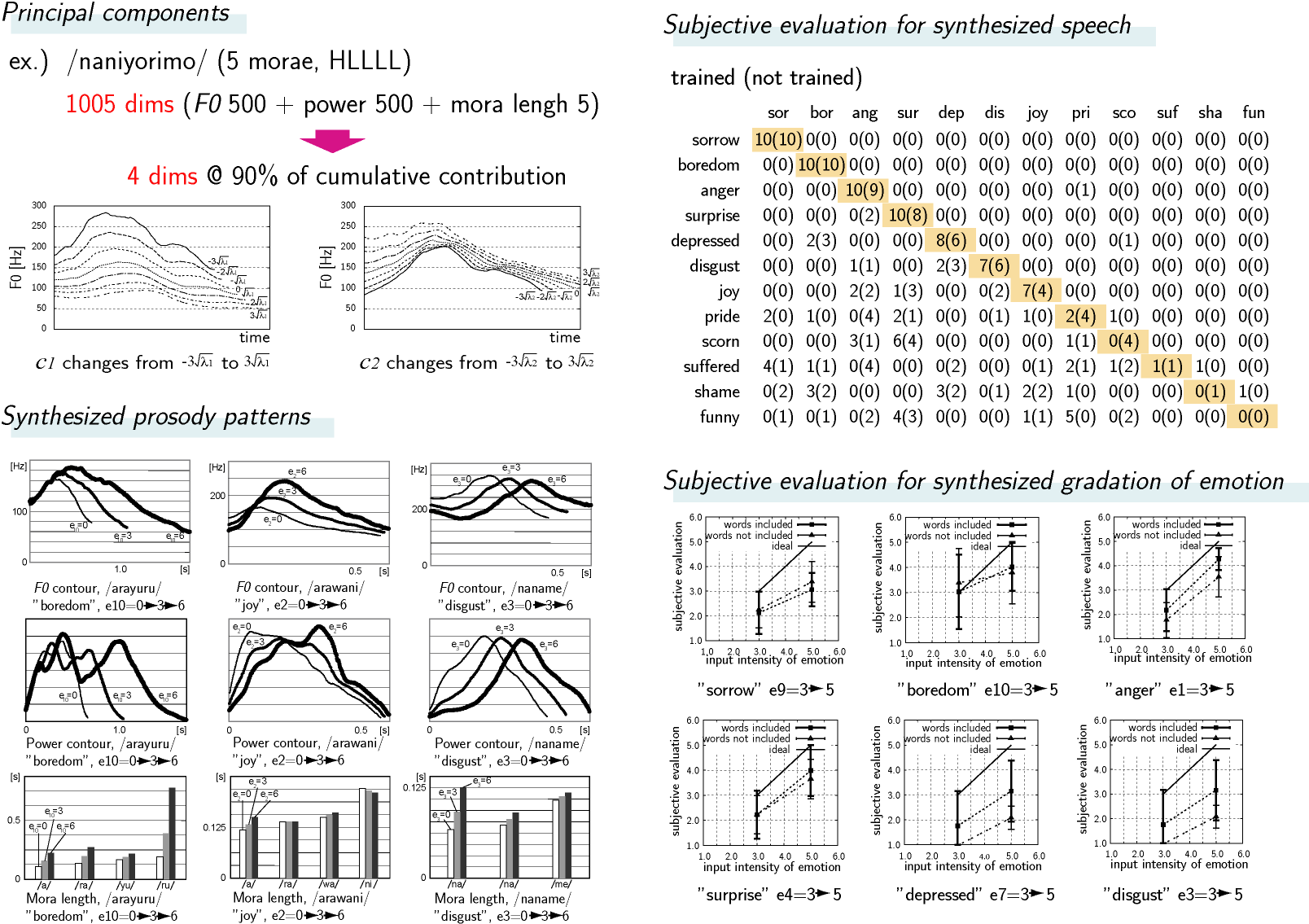
任意のテキスト(単語、文、文章)に対して、データベースに格納した音韻ごとの音声波形を接続して合成音声を得る方法を波形接続方式と言う。これは実際に人が話した声を接続するので、一般に自然性が高い。しかし、データベースに格納されている音声しか合成できないため、様々な感情を含んだ音声を合成するためには大量の音声を用意しなくてはならなかった。本方式では、ある言葉が様々な感情を含んで話される音声の集合が、『平均的な話し方を中心とするばらつき』として表現できると仮定し、学習音声群から主成分分析を使って「感情音声空間」を構築することにより、学習音声には含まれない感情音声も合成することを可能にした。
本手法は、Active Shape Models (ASM)の音声版と見ることもできる。
中高型のアクセントを持つ/naname/に「怒り」を含んだ場合を考えると、第2モーラの/na/によりストレスが置かれる。同じアクセント型を持つ/erabu/や/kowai/も同じ傾向があると考えられる。それに対して頭高型の/naniyorimo/では、第1モーラの/na/によりストレスが置かれ、中高型とは異なる韻律パターン(話し方=声の高さと大きさ、それぞれの軌跡、各モーラの長さ)の変化が観察される。そこで本方式では、モーラ数とアクセント型の組み合わせ(言葉の“型”と呼ぶ)が、感情を含んだ時に生ずる韻律パターンの変化を決めると仮定する。
すなわち、下表に挙げる20通りの言葉の“型”それぞれについて、代表として1語(例: 2モーラHL型については/nama/)ずつ選び、各々様々な感情を含んで話した音声を集める。
モーラ数 |
アクセント型 |
文節語 |
|
|---|---|---|---|
2 |
HL |
/nama/ |
|
LH |
/nami/ |
||
3 |
HLL |
/midori/ |
|
LHL |
/naname/ |
||
LHH |
/nagame/ |
||
4 |
HLLL |
/arawani/ |
|
LHLL |
/amamizu/ |
||
LHHL |
/arayuru/ |
||
LHHH |
/omonaga/ |
||
5 |
HLLLL |
/naniyorimo/ |
|
LHLLL |
/amamizuwa/ |
||
LHHLL |
/amanogawa/ |
||
LHHHL |
/yawarageru/ |
||
LHHHH |
/amarimono/ |
||
6 |
HLLLLL |
/emoiwarenu/ |
|
LHLLLL |
/omoumamani/ |
||
LHHLLL |
/amagaeruwa/ |
||
LHHHLL |
/iwazumogana/ |
||
LHHHHL |
/oborozukiyo/ |
||
LHHHHH |
/warawaremono/ |
||
韻律パラメータ pi = [fi1, fi2, ..., fiL, ai1, ai2, ..., aiL, li1, li2, ..., lin] (i: i番目の学習音声、f: F0、a: 短時間平均パワー、l: モーラ長、L: 音声のサンプル数、n: モーラ数)を全ての学習音声について求め、主成分分析により、韻律を平均韻律とそこからの分散の形(次式)で表現する。
![]()
| : 平均韻律、 | cij | : j番目の主成分得点、 | vj | : j番目の固有ベクトル |
ciを与えることで、感情音声の韻律パターンpを合成することができる。文節語を合成する際は、平静音声から作成した音韻データベースから当該素片を取り出し、pを使ってTD-PSOLA法で音声波形を合成する。固有ベクトルvjの張る空間が韻律の部分空間、すなわち感情音声空間である。
同じ学習音声を被験者に聴かせ、K個の感情語の強度に関する主観評価ベクトルeiを得る。今回の実験では、「怒り」「喜び」「嫌悪」「驚き」「侮り」「誇り」「落胆」「おかしい」「悲しい」「退屈」「苦しい」「羞恥」の12感情語について行った(K=12)。
次に、主観評価ベクトルeを説明変数、主成分得点ベクトルcを目的変数として重回帰分析を行うことで、これらが次の線形式で結合できる。Rは偏回帰係数行列である。これで感情ベクトルeを与えれば、合成すべき韻律パターンpが求められる。
![]()
学習音声はモーラ数とアクセント型の組合せ(上記)20通り×47感情の計940音声収録した。下表に、4モーラでLHHL型の文節語/arayuru/の47感情音声を示す。
平静** |
|||
* 全データセットは、国立情報学研究所音声資源コンソーシアムにて「 慶應義塾大学 研究用感情音声データベース (Keio-ESD) 」として公開されています。
** 話者が表現しようと試みた感情語。(手法上できるだけバラィエティーに富んだ韻律パターンが収集できれば良いので、正しくその感情が表現されている必要はない。各学習音声に含まれる感情は、上記12感情それぞれについて7段階評価を行う主観評価実験によって聴き手の知覚する感情を抽出する。)
{kind=link}
{kind=link}