Title: Synthesize Emotional Speech (Synthesis of emotional speech using subspace constraints in prosody)
![]() Examples
of synthesized speech :Synthesis
of emotional speech using subspace
constraints in prosody
Examples
of synthesized speech :Synthesis
of emotional speech using subspace
constraints in prosody
Our method can synthesize emotion with its gradation.
target emotion
|
words (accent,
# of morae, trained/not-trained)
|
emotion
intensity
|
"anger"
|
/amamizu/ (LHLL, 4, trained)
|
|
"boredom"
|
/aomori/ (LHLL, 4, not trained)
|
|
"joy"
|
/arawani/ (HLLL, 4, trained)
|
|
"sorrow"
|
/omoumamani/ (LHLLLL, 6, trained)
|
|
"disgust"
|
/naname/ (LHL, 3, trained)
|
|
"depression"
|
/oborozukiyo/ (LHHHHL, 6, trained)
|
*** emotion vector e given here was [6 0 0 0 0 0 0 0 0 0 0 0]T.
Concatinative approach in synthesizing speech demonstrated to be most promising for achieving human-like quality because it concatenates human voice segments stored in the database. In other words, conventional concatinative systems only synthesize what are stored in the database. Yet, It has a difficulty in collecting enough variety of waveforms in the database for synthesizing various kinds and gradations of emotional content, depending on the required degrees of freedom in possible emotional context.
We have analyzed speech data that contained a variety of emotions, and found the prosody patterns (=speaking styles, i.e., contours of F0 and power, lengths of the morae) approximately distributed in the normal distribution (mean and the variation from it). We use principal component analysis for effectively parameterizing the database (training speech samples) so that our system can synthesize what are actually NOT stored in the training samples as well.
This method can be viewed as the speech version of the Active Shape Models.
![]() Same
linguistic structure gives same motions in prosody
Same
linguistic structure gives same motions in prosody
When the word /naname/ (3 morae, LHL) conveys "anger", the speaker puts more stress on the 2nd mora due to the location of accent. The same phenomenon is observed with other words that share the same linguistic structure such as /erabu/ and /kowai/. /Naniyorimo/, on the other hand, has the accent on the 1st mora, and the speaker puts more stress on it when conveying "anger". We assume motions of speech prosody when the speech conveys emotion are dependent on the combiation of the number of morae and the accent location.
We chose a representative word for each of 20 combinations in the following table, for which we collected speech samples with a variety of emotions. For instance, /nama/ was chosen for 2 morae and HL accent.
#
of morae
|
accent
locations
|
words
|
|
|---|---|---|---|
2
|
HL
|
/nama/
|
|
LH
|
/nami/
|
||
3
|
HLL
|
/midori/
|
|
LHL
|
/naname/
|
||
LHH
|
/nagame/
|
||
4
|
HLLL
|
/arawani/
|
|
LHLL
|
/amamizu/
|
||
LHHL
|
/arayuru/
|
||
LHHH
|
/omonaga/
|
||
5
|
HLLLL
|
/naniyorimo/
|
|
LHLLL
|
/amamizuwa/
|
||
LHHLL
|
/amanogawa/
|
||
LHHHL
|
/yawarageru/
|
||
LHHHH
|
/amarimono/
|
||
6
|
HLLLLL
|
/emoiwarenu/
|
|
LHLLLL
|
/omoumamani/
|
||
LHHLLL
|
/amagaeruwa/
|
||
LHHHLL
|
/iwazumogana/
|
||
LHHHHL
|
/oborozukiyo/
|
||
LHHHHH
|
/warawaremono/
|
||
![]() A
Synthesis Method of Emotional Speech Using Subspace Constraints in Prosody
A
Synthesis Method of Emotional Speech Using Subspace Constraints in Prosody
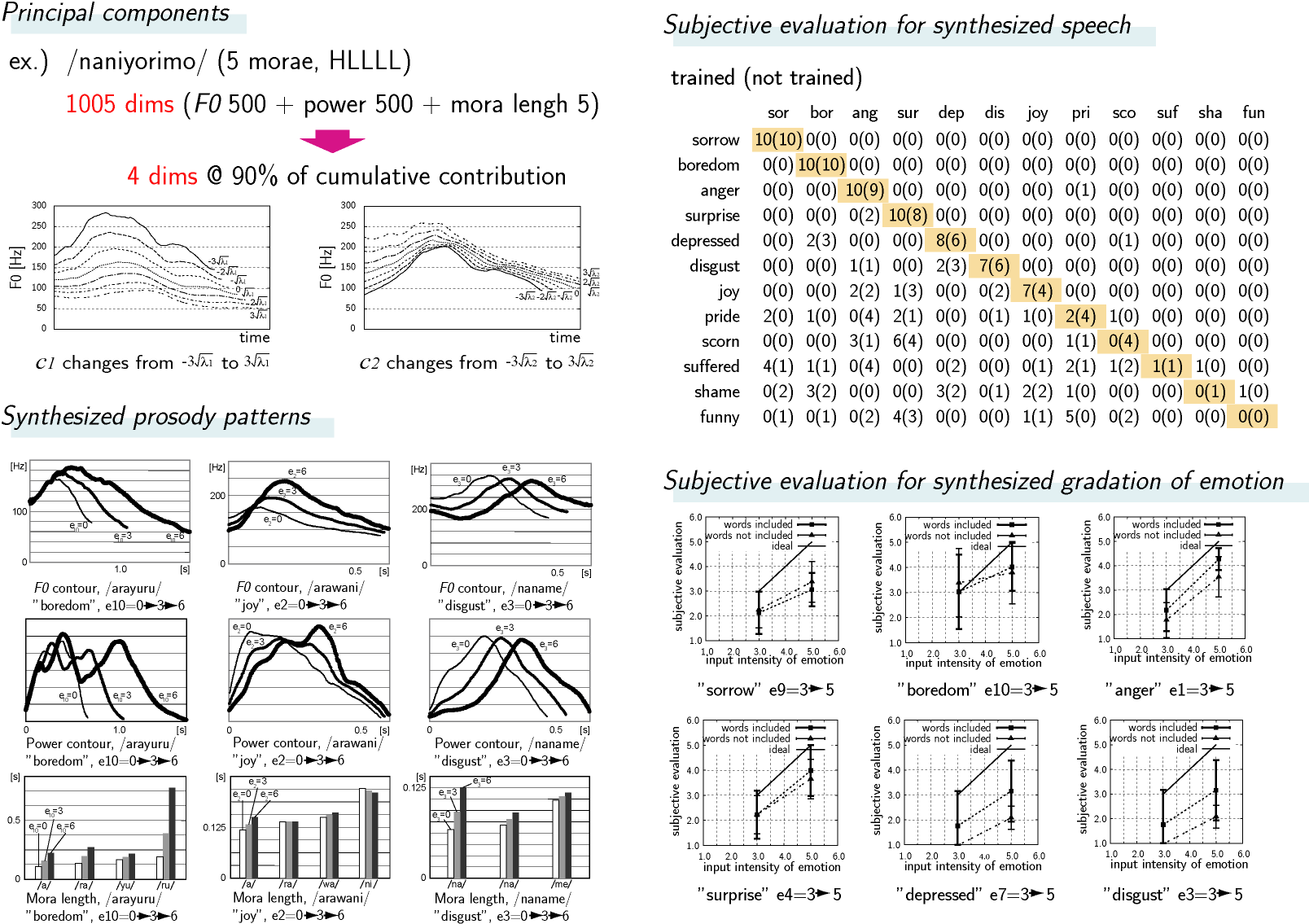
Firstly, prosody patterns pi = [fi1, fi2, ..., fiL, ai1, ai2, ..., aiL, li1, li2, ..., lin] ( i: i-th training speech, f: F0, a: power, l: mora length, L: speech length, n: the number of morae) extracted from training speech samples are analysized by principal component analysis to obtain the following formulation that is summation of the mean and the variance from it:
![]()
| : mean prosody pattern, | : j-th principal component score, | : j-th eigenvector |
Principal component vector ci gives prosody pattern pi of i-th training speech. When synthesizing a word utterance, the system assemples wavelets from phoneme database, that contains netural utterances, and generates the waveform using TD-PSOLA with p.
Secondly, subjective evaluation for each training speech sample gives K-dimensional emotion vector ei. In this implementation, we used 12 emotions that include "anger", "joy", "disgust", "surprise", "despise", "pride", "depression", "amusing", "sorrow", "boredom", "suffering", and "shame" (K=12).
Finally, multiple regression analysis where emotion vector e gives the predictor variables and principal component vector c the criterion variables estimates the partial regression coefficients R that linearly relate them by the equation below. Thus, prosody pattern p to be synthesized can be obtained from emotion vector e that is given.
![]()
Here show the examples of training speech samples for a Japanese word /arayuru/ (the number of morae = 4, accent type = LHHL). A single male speaker expressed 47 emotions for each of 20 combinations of the number of morae and accent types.
neutral**
|
|||
* Full dataset is available from here (as Keio University Japanese Emotional Speech Database (Keio-ESD), Speech Resources Consoutium, The National Institute of Informatics).
** Emotions that the speaker tried to express (They are not necessarily conveyed successfully, nor is required in the method.)
{kind=link}
{kind=link}